
GDELT
A quick overview of GDELT public data set:
“GDELT Project monitors the world’s broadcast, print, and web news from nearly every corner of every country in over 100 languages and identifies the people, locations, organisations, counts, themes, sources, and events driving our global society every second of every day, creating a free open platform for computing on the entire world“
Such a dataset is a perfect match for machine learning, and an excellent use case for getting started with Spark and Hadoop Input Format. I won’t report here the data format specification, but have a look there. For this exercise I’m using “GDELT Event Database” data set only that fits into simple JSON events.
The goal of this exercise is to do the following:
- Create an Hadoop GDELT -> Json InputFormat
- Read data from Spark shell
- Convert Json object as Spark SQL table
- Query table and extract result (Goldstein Scale)
Well, quite a challenge indeed… However, if you’re not visiting my blog for the first time, the concept of InputFormat should be familiar. If not, have a look at my previous posts. Only Spark (and Spark-SQL) is a new concept here.
Create a GDELT -> Json Parser
GDELT Data are tab separated values. We can easily parse data and store each key value pair as a JSON element. However, I want to get nested entities (such as eventGeo, actor1Geo, actor2Geo, actor1Codes, actor2Codes) as their keys will always be the same. My final JSON structure looks like the following:
{
"isRoot": true,
"eventGeo": {
"countryCode": "US",
.../...
},
"actor1Code": {
"code": "BUS",
.../...
},
"actor2Code": {
"code": "BUS",
.../...
},
"actor1Geo": {
"countryCode": "US",
.../...
},
"actor2Geo": {
"countryCode": "US",
.../...
},
"goldsteinScale": 6,
"quadClass": 2,
"month": 201409,
"GlobalEventID": 313271341,
.../...
}
To get from a bunch of raw file to structured Json, I’m using nothing more than a standard InputFormat with standard RecordReader. Whenever a new line is consumed, I send it to my Json parser and output the result to the hadoop framework.
while (pos < end) {
// Let Hadoop LineReader consume the line into tmp text...
newSize = in.readLine(tmp,
maxLineLength, Math.max((int) Math.min(Integer.MAX_VALUE, end - pos),
maxLineLength));
// ... Take the result and feed my parser
// tmp is the raw data
// value will be the expected JSON object
value.set(parse(tmp.toString()));
if (newSize == 0) {
break;
}
pos += newSize;
if (newSize < maxLineLength) {
break;
}
Have a look at com.aamend.hadoop.format.GdeltRecordReader class on my Github account. Before you might say anything, note that performance is out of the scope of that study 🙂 . I’m basically using google json-simple as a third part dependency (see below maven deps). Raw files being stored on HDFS, any event read through my GdeltInputFormat.class will be actually seen as a JSON object.
com.googlecode.json-simple json-simple 1.1
Do not forget to add these dependencies to your Spark job! I’m building a fat jar for that purpose (refer to previous post).
Read data from spark shell
Assuming you get a spark distribution up and running, simply start a shell session as follows. Note the “–jars” options that will add all your dependencies to your classpath.
spark-shell --jars spark-1.0-SNAPSHOT-jar-with-dependencies.jar
Let’s get deeper into that spark shell session. I’m using newAPIHadoopFile from the sparkContext in order to read Hadoop file with a custom InputFormat. I need to supply here the input path and the InputFormat to be used. I also need to provide spark context with the expected Key / Value class of my InputFormat implementation.
import com.aamend.hadoop.format.GdeltInputFormat import org.apache.hadoop.io.Text // Read file from HDFS - Use GdeltInputFormat val input = sc.newAPIHadoopFile( "hdfs://path/to/gdelt", classOf[GdeltInputFormat], classOf[Text], classOf[Text] )
We now have a HadoopRDD (containing key / value pairs), but still not the bunch of String (json) we expected. Conversion is done as follows
// Get only the values from Hadoop Key / Values pair
val values = input.map{ case (k,v) => v}
// Need to deserialize Text
val json = values.map(t => t.toString)
OK, we’re good to go. Spark is able to read our Json GDelt files. Not convinced ? Print out the first 3 lines as follows
values.take(3).foreach(println)
Convert Json object as Spark SQL table
Spark SQL can be used through the Spark SQLContext. Although it does not physically create any Table, it maps the supplied RDDs into a SchemaRDD that can be queried from SQL.
import org.apache.spark.sql.SQLContext // Access spark SQL context val sqlContext = new SQLContext(sc) // Load JSON (String) as a SQL JsonRDD val jsonRDD = sqlContext.jsonRDD(json)
We can make sure the extracted data structure is correct using below command. Quite handy, isn’t it ? Fields will be treated as String, Integer or Double, etc.. depending on their Json value.
jsonRDD.printSchema()
root |-- GlobalEventID: integer (nullable = true) |-- actor1Code: struct (nullable = true) | |-- code: string (nullable = true) | |-- countryCode: string (nullable = true) | |-- ethnicCode: string (nullable = true) | |-- knownGroupCode: string (nullable = true) | |-- name: string (nullable = true) | |-- religion1Code: string (nullable = true) | |-- religion2Code: string (nullable = true) | |-- type1Code: string (nullable = true) | |-- type2Code: string (nullable = true) | |-- type3Code: string (nullable = true) |-- actor1Geo: struct (nullable = true) | |-- adm1Code: string (nullable = true) | |-- countryCode: string (nullable = true) | |-- featureId: integer (nullable = true) | |-- lat: double (nullable = true) | |-- long: double (nullable = true) | |-- name: string (nullable = true) | |-- type: integer (nullable = true) |-- actor2Code: struct (nullable = true) | |-- code: string (nullable = true) | |-- countryCode: string (nullable = true) | |-- ethnicCode: string (nullable = true) | |-- knownGroupCode: string (nullable = true) | |-- name: string (nullable = true) | |-- religion1Code: string (nullable = true) | |-- religion2Code: string (nullable = true) | |-- type1Code: string (nullable = true) | |-- type2Code: string (nullable = true) | |-- type3Code: string (nullable = true) |-- actor2Geo: struct (nullable = true) | |-- adm1Code: string (nullable = true) | |-- countryCode: string (nullable = true) | |-- featureId: integer (nullable = true) | |-- lat: double (nullable = true) | |-- long: double (nullable = true) | |-- name: string (nullable = true) | |-- type: integer (nullable = true) |-- avgTone: double (nullable = true) |-- dateAdded: string (nullable = true) |-- day: string (nullable = true) |-- eventBaseCode: string (nullable = true) |-- eventCode: string (nullable = true) |-- eventGeo: struct (nullable = true) | |-- adm1Code: string (nullable = true) | |-- countryCode: string (nullable = true) | |-- featureId: integer (nullable = true) | |-- lat: double (nullable = true) | |-- long: double (nullable = true) | |-- name: string (nullable = true) | |-- type: integer (nullable = true) |-- eventRootCode: string (nullable = true) |-- fracDate: double (nullable = true) |-- goldsteinScale: double (nullable = true) |-- isRoot: boolean (nullable = true) |-- month: integer (nullable = true) |-- numArticles: integer (nullable = true) |-- numMentions: integer (nullable = true) |-- numSources: integer (nullable = true) |-- quadClass: integer (nullable = true) |-- sourceUrl: string (nullable = true) |-- year: integer (nullable = true)
Assuming the data structure is now correct, we register this SchemaRDD as a Spark table. Let’s now play with SQL !
jsonRDD.registerAsTable("gdelt")
Query table and extract result (Goldstein Scale)
Definition of Goldstein scale taken from GDELT website: “Each CAMEO event code is assigned a numeric score from -10 to +10, capturing the theoretical potential impact that type of event will have on the stability of a country“. Ranks can be found there.
We will try to get an average Goldstein scale for any article involving France as primary actor and United Kingdom as secondary one. Is France willing to declare war to UK based on the past few days events ? Hopefully not, but let’s get some proofs 🙂
val relations = sqlContext.sql(
"SELECT day, AVG(goldsteinScale) " +
"FROM gdelt WHERE " +
"actor1Geo.countryCode = 'FR' AND actor2Geo.countryCode = 'UK' " +
"GROUP BY day")
Note the nestedEntity query (actor2Geo.countryCode) used because of my Json structure. Such nested structure makes my SQL even more readable
We finally save our final RDD as a text file(s) in HDFS, … and …
relations.map(row => row(0) + "\t" + row(1)).saveAsTextFile("hdfs://output/path")
… And plot data into a Graph
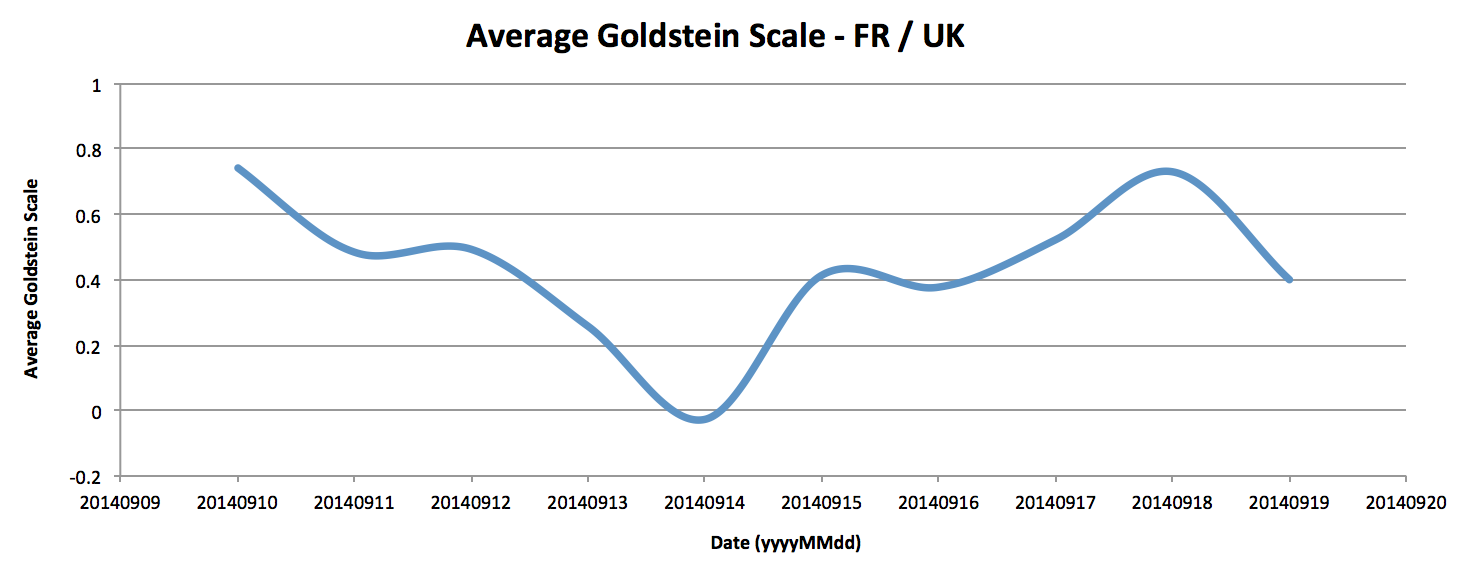
Well, It looks like I can stay in the UK for a while 🙂
Anyway, I’ve learned a lot for this exercise, so I hope you did enjoy reading too. Please find my code on Github / Spark project (Github), and should you have any question, feel free to ask.
Cheers!
Antoine
Use case: Ukraine Russia relations over the past 30 years
Using such a record reader, you can build the following graph. I’ve reported the Ukraine – Russia diplomatic relations for the past 30 years.
Even better, you can smooth such a goldstein scale by using a moving average (5,10 and 30 days in below example). Such moving average has been built on scala / spark (see : MovingAverageGoldstein.scala)

Enjoy !

Very cool!
Thanks for sharing!
David
In this example why did you choose to use JSON rather than pure delimited data?
Cheers
David
Well, because I wanted to learn SparkSQL 🙂
I could have used a pure delimited data for that particular example, but the main reason I use Json / SparkSQL is that I’ve exported this structured table to my Hive metastore. Once on Hive, you will be able to query over and over (through SparkSQL) until you find some other good stuff